Joint Distribution Adaptation
Transfer Feature Learning with Joint Distribution Adaptation
COMP7404 Group16 | Quziqi, He Qing, Lu Zhihua, Liu Zhengyang
Paper Introduction Video
Quick Results Overview
About JDA
Problem Statement
Domain adaptation aims to learn effective classifiers for target domains with only labeled source data. The key challenge is that source and target domains often have different distributions.
minA Σc=0 tr(ATX McXTA) + λ‖A‖²
s.t. ATXHXTA = I
Where M0 is the marginal distribution MMD and Mc (c>0) are conditional distribution MMDs.
Key Contributions
Joint Adaptation
Simultaneously adapts both marginal P(Xs) ≈ P(Xt) and conditional P(Y|Xs) ≈ P(Y|Xt) distributions
Iterative Refinement
Uses pseudo-labels to iteratively improve conditional distribution adaptation
Feature Transformation
Learns optimal projection A such that Z = ATX minimizes domain discrepancy
Comprehensive Results
Outperforms state-of-the-art methods on digit recognition, object classification, and face recognition
Algorithm Flow
JDA iteratively refines pseudo-labels for target domain to improve conditional distribution adaptation
Experimental Results - Accuracy Comparison
Format: Ours (Paper), showing reproduction results (paper reported values).
| Task | Type | NN | PCA | GFK | TCA | TSL | JDA |
|---|
Figure 3 - Cross-Domain Accuracy Overview
Accuracy on 36 cross-domain image tasks across 4 dataset types (Digit, COIL, PIE, SURF/Office), showing knowledge adaptation under different transfer difficulties.
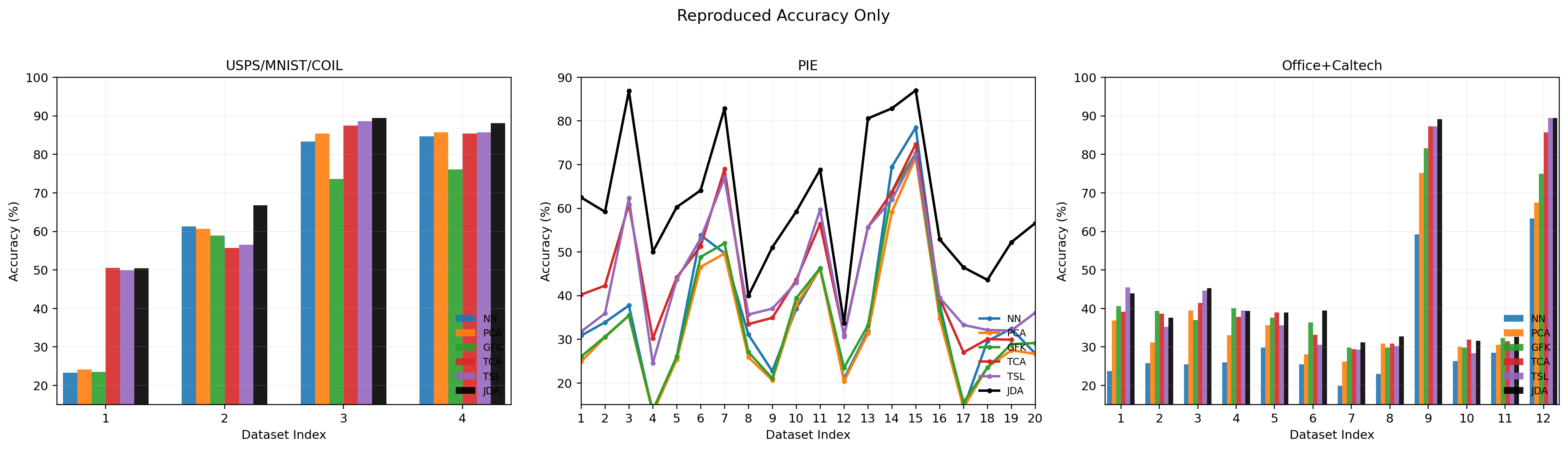
Accuracy (%) on 4 types of 36 cross-domain image datasets
Figure 4 - Effectiveness Verification
PIE1→PIE2 task: Accuracy and MMD Distance vs iterations (data from fig4_results.csv)
(a) Accuracy vs #Iterations
(b) MMD Distance vs #Iterations
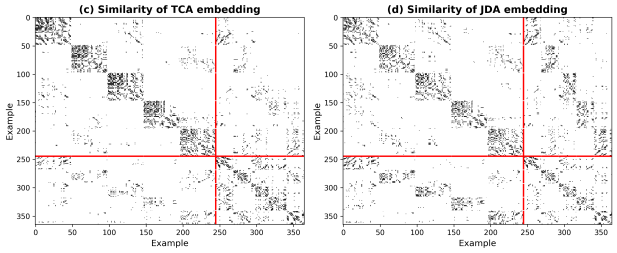
(c) TCA & (d) JDA Similarity Matrices
Figure 5 - Parameter Sensitivity & Convergence
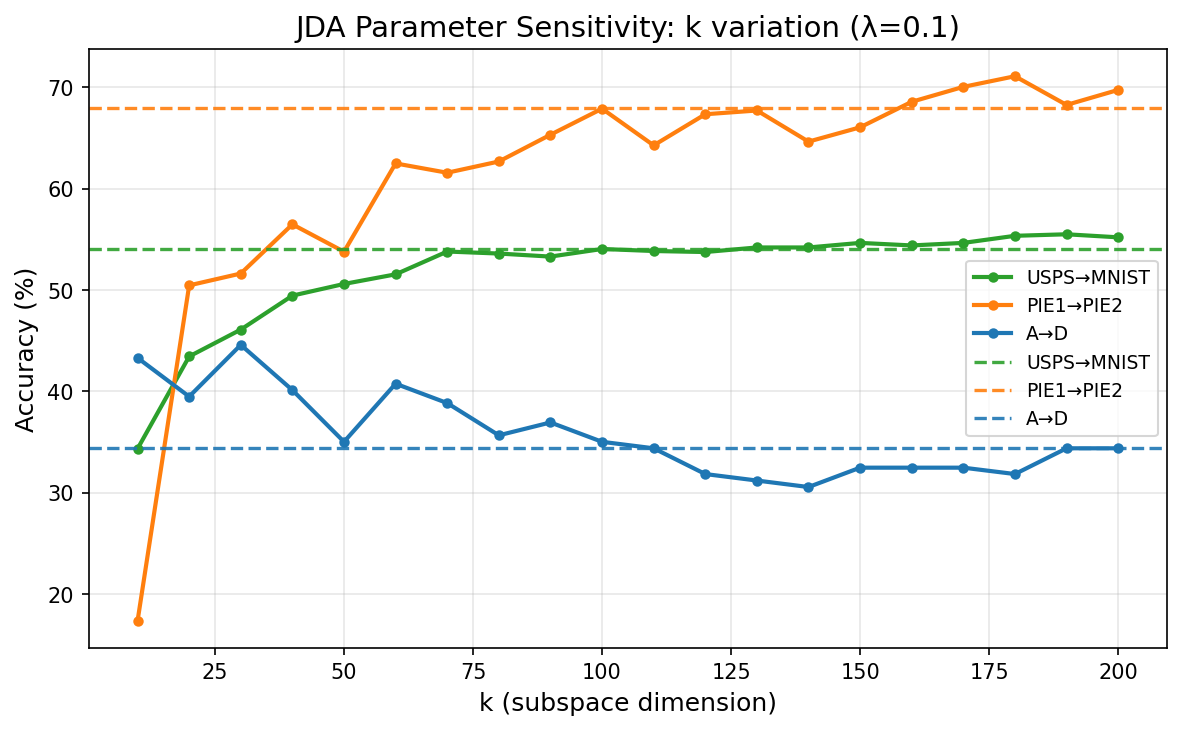
(a) k Sensitivity
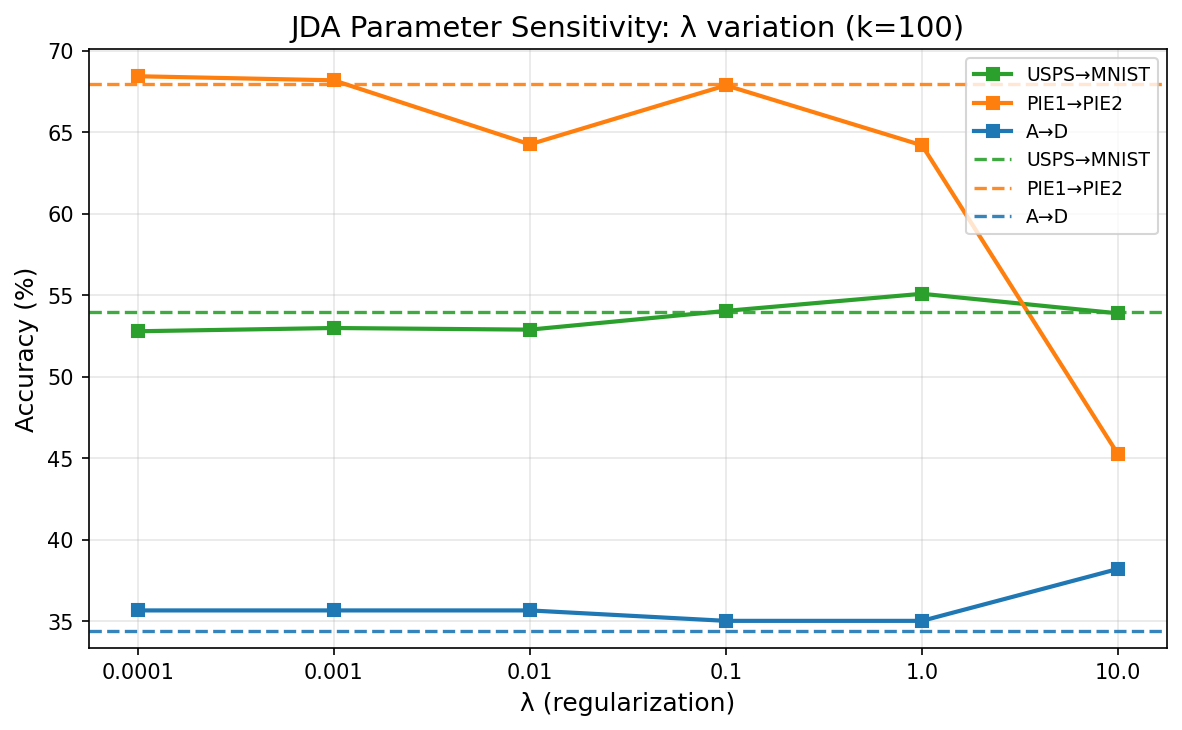
(b) λ Sensitivity
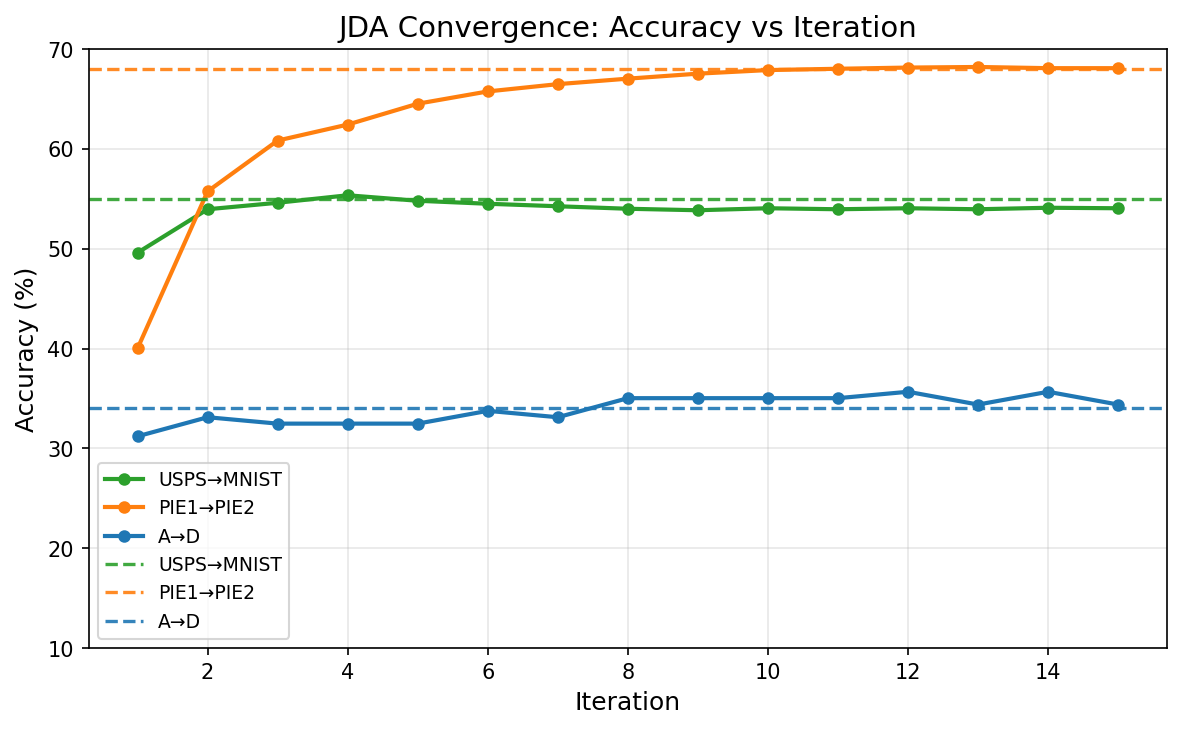
(c) Accuracy Convergence
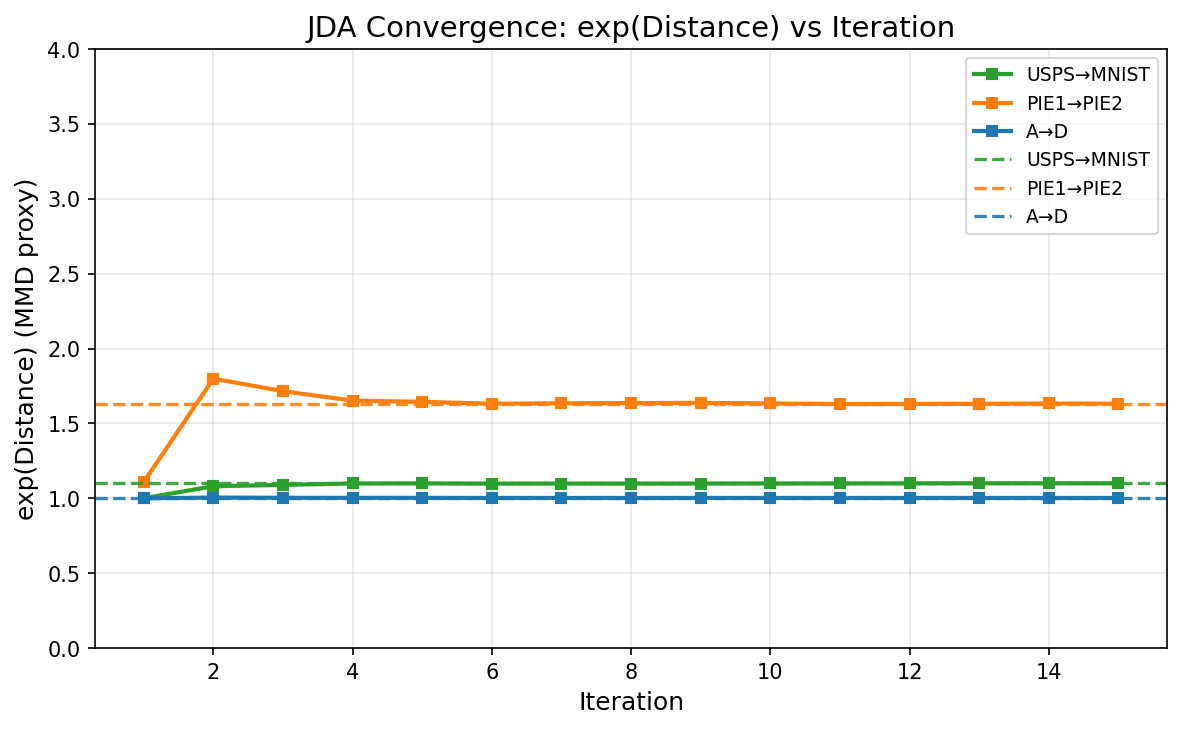
(d) Distance Convergence
Method Comparison by Dataset Type
Data source: Embedded 36 cross-domain task results (Paper + Ours), see data.json / _embedded_data.txt.
Average Accuracy by Method
Performance by Dataset Type
JDA: Ours vs Paper
Comparing reproduced JDA with paper-reported JDA accuracy, diff = Ours - Paper.
| Dataset Type | JDA (Ours) | JDA (Paper) | Difference (Ours − Paper) |
|---|
About This Reproduction
Paper Information
Title: Transfer Feature Learning with Joint Distribution Adaptation
Authors: Mingsheng Long, Jianmin Wang, Guiguang Ding, Jiaguang Sun, Philip S. Yu
Conference: ICCV 2013
Datasets Used
- Digit: USPS, MNIST (2 tasks)
- COIL: COIL1, COIL2 (2 tasks)
- PIE: PIE1-5 permutations (20 tasks)
- SURF/Office: Caltech, Amazon, Webcam, DSLR (12 tasks)
Reproduction Summary
| Total Tasks | 36 |
| Methods | NN, PCA, GFK, TCA, TSL, JDA |
| Avg JDA (Paper) | - |
| Avg JDA (Ours) | - |
| Avg Difference | - |
GitHub Repository
Scan to Access
